


L’objectif de cet article est d’étudier une étude de cas pratique : mettre en place un nœud IPFS sous une distribution Linux basé sur debian.
Installation du serveur IPFS
sudo apt install golang -y
wget https://dist.ipfs.io/go-ipfs/v0.14.0/go-ipfs_v0.14.0_linux-amd64.tar.gz$
tar xvfz go-ipfs_v0.14.0_linux-amd64.tar.gz
La configuration d’un nœud local se fait simplement en suivant les instructions données par l’exe.
./ipfs init
./ipfs cat /ipfs/XxXX/readme
./ipfs daemon
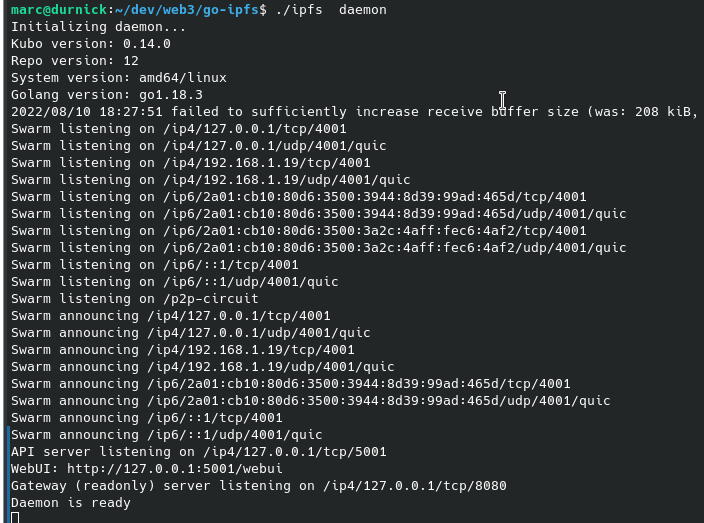
Le nœud est ensuite opérationnel et consultable sur l’url local suivante :
L’ajout d’un fichier à l’aide de la ligne de commande se fait via : ./ipfs add ../merle.jpg
Cette commande vous affichera le hash correspondant à votre fichier :

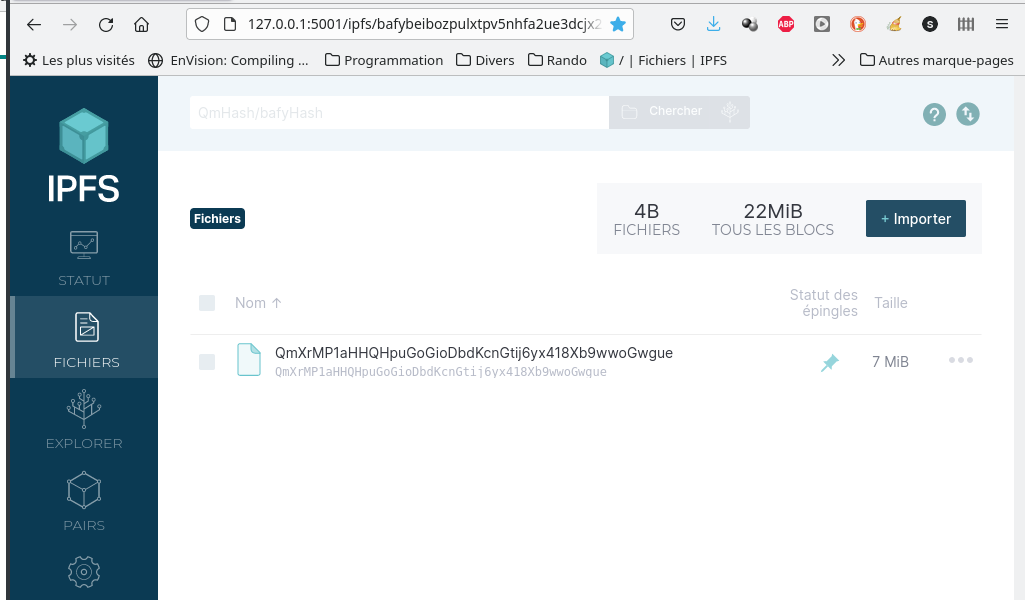
Cette valeur ( QmXrMP1aHHQHpuGoGioDbdKcnGtij6yx418Xb9wwoGwgue ) correspond à l’identifiant unique de votre fichier. Il peut ensuite être utilisé pour localiser ou faire des actions dessus.
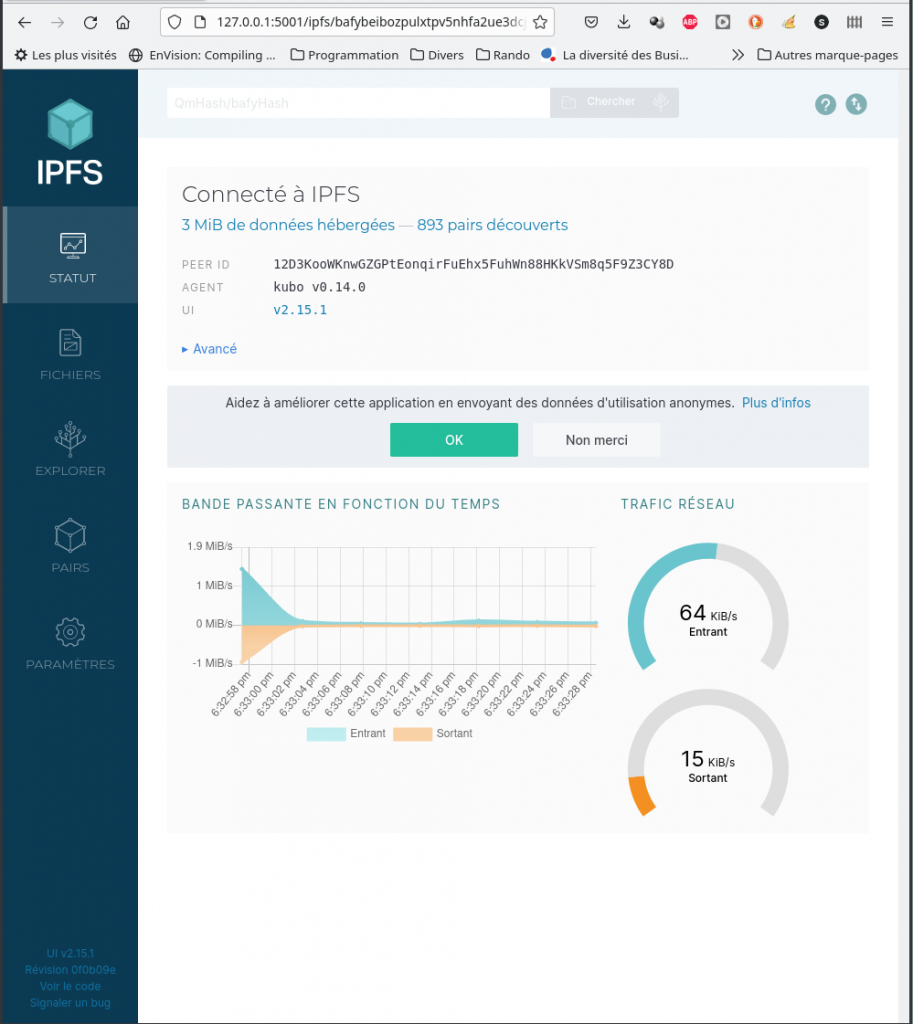
Depuis l’interface Web, il est possible de vérifier l’enregistrement de votre fichier :
Toutes les actions faisables en ligne sont réalisables depuis la console.
La suppression via rm, l’étiquetage, via pin add pour l’étiquetage de fichier.
La mise en place de ce type de service est ultra-basique. Il est recommandé d’utiliser un service d’étiquetage centralisé pour faciliter la diffusion de ses fichiers. Une fois ceci fait, on peut se lancer dans d’autres expériences : la publication d’un site web statique directement en IPFS, l’hébergement d’une collection de NTF.
L’objectif est de pouvoir proposer de manière simple ces fichiers au plus grand nombre sans risque de défaillance d’un serveur centralisé.
Nota : cet article est assez court mais a pour objectif d’être le premier dans ma découverte du web3. A suivre donc ^^
Référence :