
L’objectif de cet article est donc de montrer une chaîne complète de traitement de l’information, permettant à partir d’un ensemble de fichier résultat de type CSV, d’aller à un tableau formaté, pouvant être directement diffusé.
![]()
Le choix des données initiales
Pour avoir une base de travail, le plus simple est de partir sur des données issues de l’Open Data. Ces données sont facilement accessibles, fournies dans un résultat exploitable .. et sont souvent des mines d’information.
Mon choix c’est fait sur la base de données Transparence. Ces données sont directement accessible sur le portail suivant : transparence-santé.
La modélisation des données est la suivante :
-
- Un fichier pour la description des entreprises
- Un fichier pour la description des avantages
- Un fichier pour la description des conventions.
La manipulation des données en Python
Nous allons faire simple, car dans ce cas précis, l’objectif est de voir comment charger les données, renseigner les jointures entre elles et produire quelques résultats.
Les données sont actuellement centrées sur l’entreprise. Notre exemple sera de construire un graphique contenant les 50 entreprises les plus dépensières (convention + avantage).
Chargement et jointure des fichiers
Pour le chargement des fichiers, le plus simple est d’utiliser les méthodes mises à disposition par le frameworks Panda. Mais avant tout chose, il est nécessaire de se faire un jeu de données possédant une taille utilisable pour les tests.
Le plus simple est de prendre une sous-sélection des fichiers de bases. Avec un environnement bash, la commande head permet de faire cela très rapidement.
head -n 50 avantage.csv > avantage_light.csv
Une bonne habitude est d’utiliser dès que possible un fichier de configuration pour votre projet. Les chaînes magiques ont malheureusement tendance à rester beaucoup trop longtemps dans les projets
DATA = {
'avantage' : 'data/avantage_light.csv',
'convention': 'data/convention_light.csv',
'entreprise': 'data/entreprise.csv',
'remuneration':'data/remuneration_light.csv'
}
Le chargement des fichiers se fait avec la commande suivante :
defloadcsv(self):
self.entreprises = read_csv(settings.DATA['entreprise'], header=0, delimiter=',', error_bad_lines=False)
self.avantages = read_csv(settings.DATA['avantage'], header=0, delimiter=';', error_bad_lines=False)
self.conventions = read_csv(settings.DATA['convention'], header=0, delimiter=';', error_bad_lines=False)
self.remunerations = read_csv(settings.DATA['remuneration'], header=0, delimiter=';', error_bad_lines=False)
Les travaux préparatoires sont maintenant terminés
Après une rapide analyse des fichiers, tous utilisent l’identifiant de l’entreprise comme données de jointure. Le seul point à prendre en compte porte sur le fait que suivant le fichier, l’identifiant n’a pas le même nom. Il faut donc préciser le nom de la colonne pour pouvoir faire un rapprochement.
La jointure se fait donc à l’aide de la commande suivante :
data_merge = merge(self.loader.avantages, self.loader.entreprises, how="left", left_on=["entreprise_identifiant"], right_on="identifiant")
data = data_merge.groupby(["secteur","entreprise_identifiant"])["avant_montant_ttc"].sum().head(50)
data.to_excel(writer, sheet_name="Avantage")
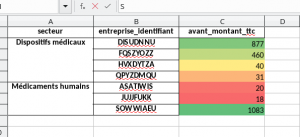
Construction du fichier excel formaté.
worksheet = writer.sheets["Avantage"]
format_size = 'C2:C'+str(data.shape[0]+1)
worksheet.conditional_format(format_size, {'type': '3_color_scale'})
worksheet.set_column('A:C', 20)
Avec ces 4 petites lignes, on a :
-
- Déterminer la taille de la table
- Changer le format de la dernière colonne (en gradiant)
- Redimensionner la taille des 3 colonnes de notre table.
Pour aller plus loin, allez faire tour sur Xlswriter. L’ensemble des sources de ce petit projet sont ici.